
VPC图是什么?
将观测值与模拟出的预测值(SPRED)放在一起比较的图表。
l 模拟出的预测值包含个体间变异的固定效应和随机效应以及残差
l 它们不同于“群体”预测(PRED)(仅有固定效应没有随机效应)和“个体” 预测(IPRED)(收缩)
VPC 图用于比较观测值和模拟预测值在特定时间或时间段内数据分布的统计数据。
l 例如:给药后1小时的中位数和与90%的区间
l 按时间顺序可以把区间可以合并在一起,创建条带状区域(但是大多数情况下条带状区域被称为“区间”)
缩略词表


绘制步骤
1.绘制散点图


图1.观测值对时间图
如图所示,这是观测值对原始时间的散点图,但对于该组数据而言,原始时间这一变量这可能不是一个最能体现vpc图包含的信息的自变量,所以我们可以尝试使用给药后时间(time after dose)这一变量作为X轴的变量,重新绘制散点图。


图2.观测值对给药后时间图
显然使用药后的时间作为自变量绘制出的图2可以更好的展示数据的特征。
2.添加5%,50%,95%分位线
基于模拟出的观测数据,在每个时间点计算出5%,50%,95%分位数,然后连接起来绘制预测区间(PI)。


图3.预测值的原始预测区间
如图3所示,这样直接绘制出的图形显示不稳定的模式,难以用它作出适当的判断,即使将实际观测数据的PI (红色的)也添加图形中(图4), 这也没有什么帮助。

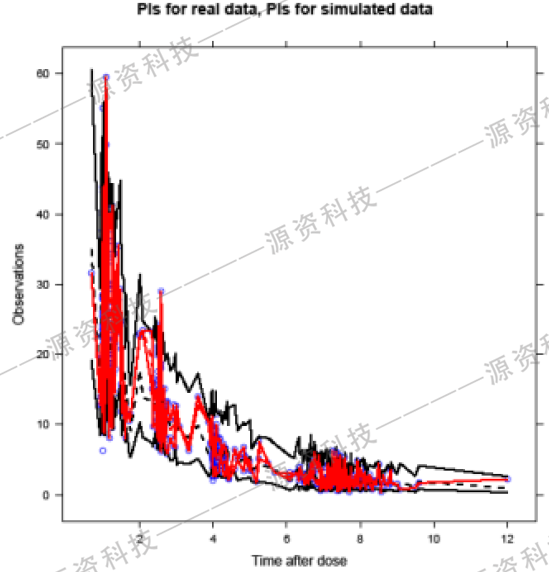
图4.预测和观察值的原始预测区间
该如何改善预测区间的不稳定模式呢?
3.对数据点进行分组
为了改善预测区间的不稳定模式,我们对图形中的数据进行分组(分段);根据采样时间,使用2,3和6小时作为边界,把数据分成四组,0-2小时组、2-3小时组、3-6小时组合6小时之后组,计算每一组数据的5%,50%,95%分位数,然后连接起来,使用这种方法分别绘制实际观测值(红色)和模拟预测值(黑色)的PI进行分析,这将有助于解释该图。


图5.将数据分成4组后绘制的观测和预测的PI区间
但是,数据分组策略的重要性如何呢?
当每个时间段(即每个小组)的分位数与下一个时间段的分位数相连时得到PI曲线,但这实际上并不能显示出我们是如何进行分组(分段)的,也没有显示出PI随着时间的推移真实的变化。
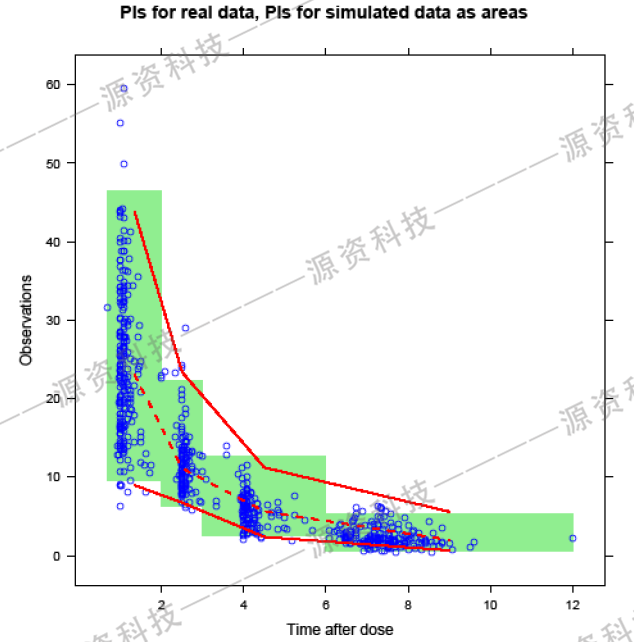

图6.预测值分为4组并以区域的方式显示PI
在图6中,我们将PI显示为”区域”(绿色区域为模拟数据的PI),这在某种意义上更加“诚实”,这显出每个分段区间的真正PI。


图7.模拟预测值分为8组并以区域的方式显示PI
图7显示了将模拟预测值分为8段的PI区间(每个分段区间中具有相似数量的数据),与之前图形的分段区间相比。 这个的分段区间怎么样?
4. 添加观测值以及它的分位线
让我们回头来比较观测数据与模拟预测的数据,将观测值的PI区间也添加到图中。相比于基于区域绘制的图形基于线条的图形可能更容易完成。(根据前面的图来选择分段区间可能更容易)。


图8.将数据分成8组后绘制的观测和预测的PI区间
图8显示出这个模型的这个vpc对于看起来非常有希望,但是我们应该怎么确定我们看到的差异并不大?
我们来看看模拟数据PI周围的置信区间。
5. 添加分位线的置信区间
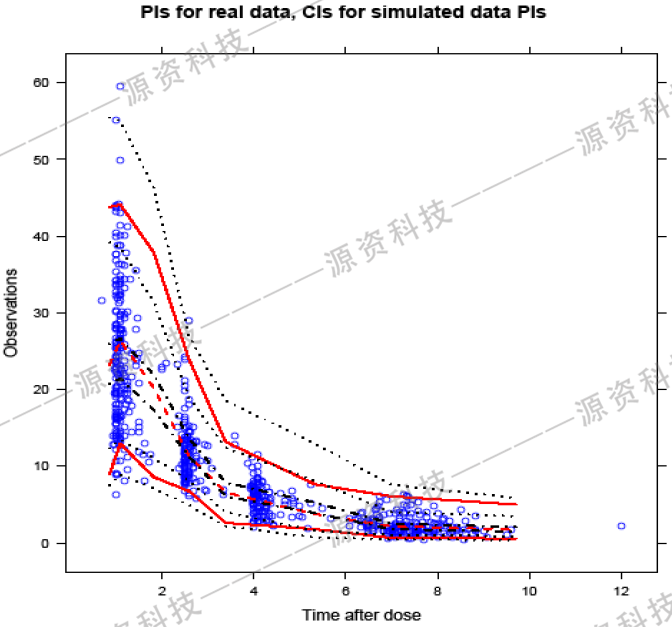

图8.将数据分成8组后绘制的观测的PI区间和预测值PI的置信区间
如图8所示,当我们在PI周围添加置信区间线条同时,我们最好隐藏掉模拟预测数据的PI线条,否则我会有太多的线条要追踪。图中红线是实际数据的PI,黑色虚线是基于模拟数据的置信区间。
这样的VPC图看起来相当不错,但也许我们可以进一步改善。

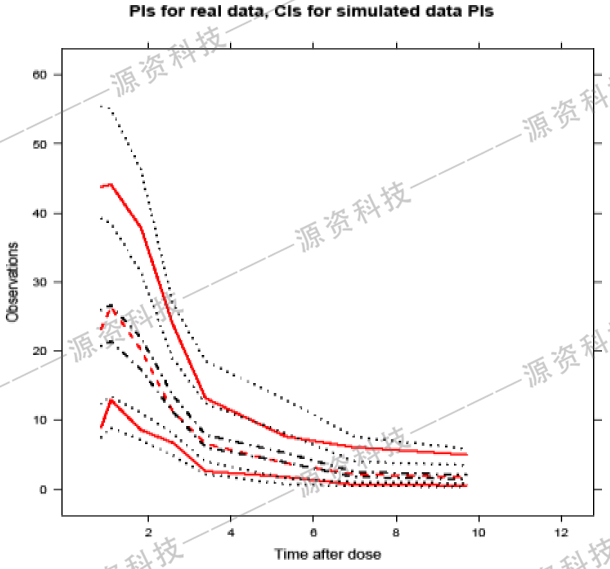
图9.观测值的PI区间与预测值PI的置信区间(无数据点)
在图9中我们将数据点全部移除。图中“CI” 与“PI”相对,因为“CI”将能够揭示数据中信息丰富和稀疏的地方,所以我么不太需要显示观测数据点。
到此我们就一步步的绘制出了我们常见的几种VPC图,更多关于Phoenix NLME,Phoenix Model,群体PKPD的信息请持续我们的官网“http://www.tri-ibiotech.com”,或者参与将于2018年5月9日举办的“第一届Certara Phoenix NLME产品研讨会”
参考文献
Mats O. Karlsson&Nick Holford,https://www.page-meeting.org/pdf_assets/8694-Karlsson_Holford_VPC_Tutorial_hires.pdf
《 Phoenix NLME User's Guide 》


