
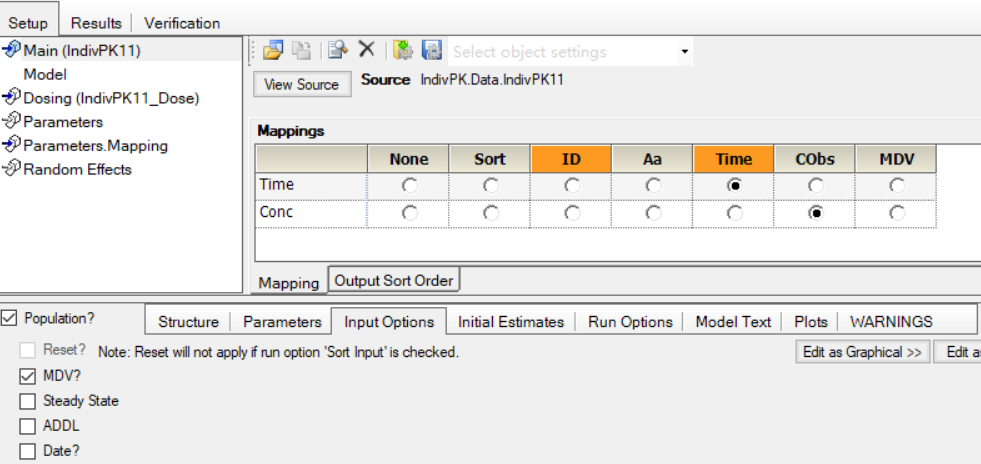
引言:Phoenix Model的“输入选项(Input Options)”选项卡的“错过此因变量的观测?(MDV?)”复选框勾选后,允许额外的映射一个“MDV”字段,以便于从原始数据集中排除掉一些数据点。
1.界面变化
1.1.勾选“日期?(Date?)”复选框前的界面:
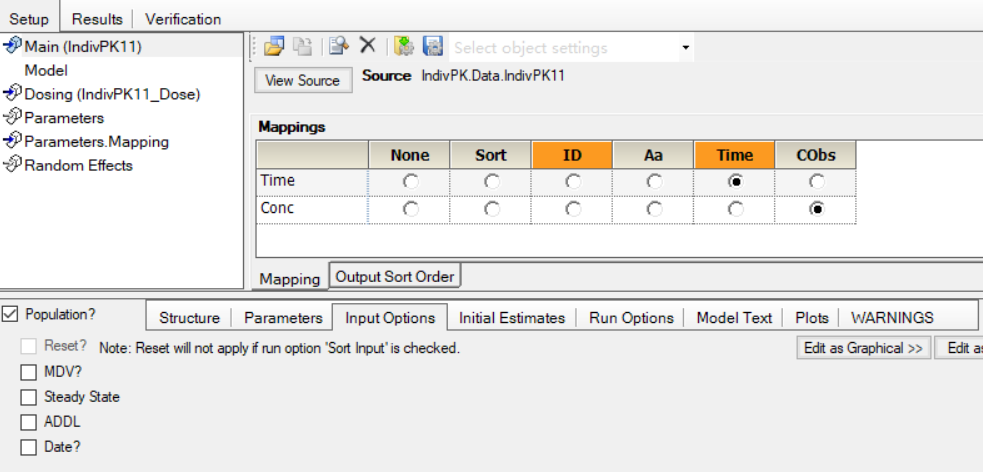
1.2.勾选“日期?(Date?)”复选框前的界面:
2.应用示例:
2.1.假设现在有一个这样的试验:
2019年3月28日是试验得第一天;
给药方案,试验第一天在上8点口服100mg药物,下午4点口服100mg药物,然后每天都重复该给药方案,持续到第4天;
采样,第1天8点给药后采集1、2、4、6时刻得血样,第4天8点给药后采集1、2、4、6时刻得血样。
2.2.数据集构建
2.2.1场景1,使用全部数据用于建模分析
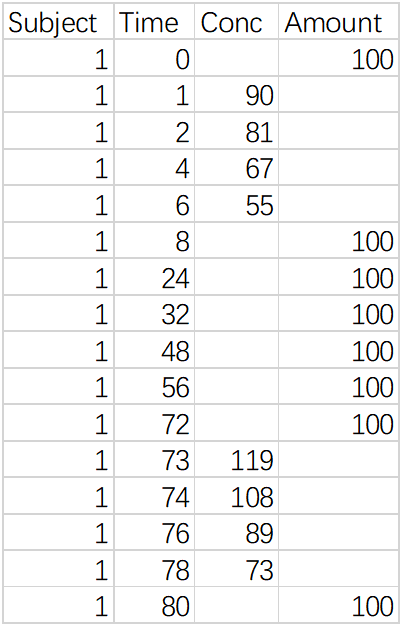
2.2.2. 场景2.仅使用第4天8点给药后的血药数据进行建模
2.2.2.1不使用MDV列构建数据集:
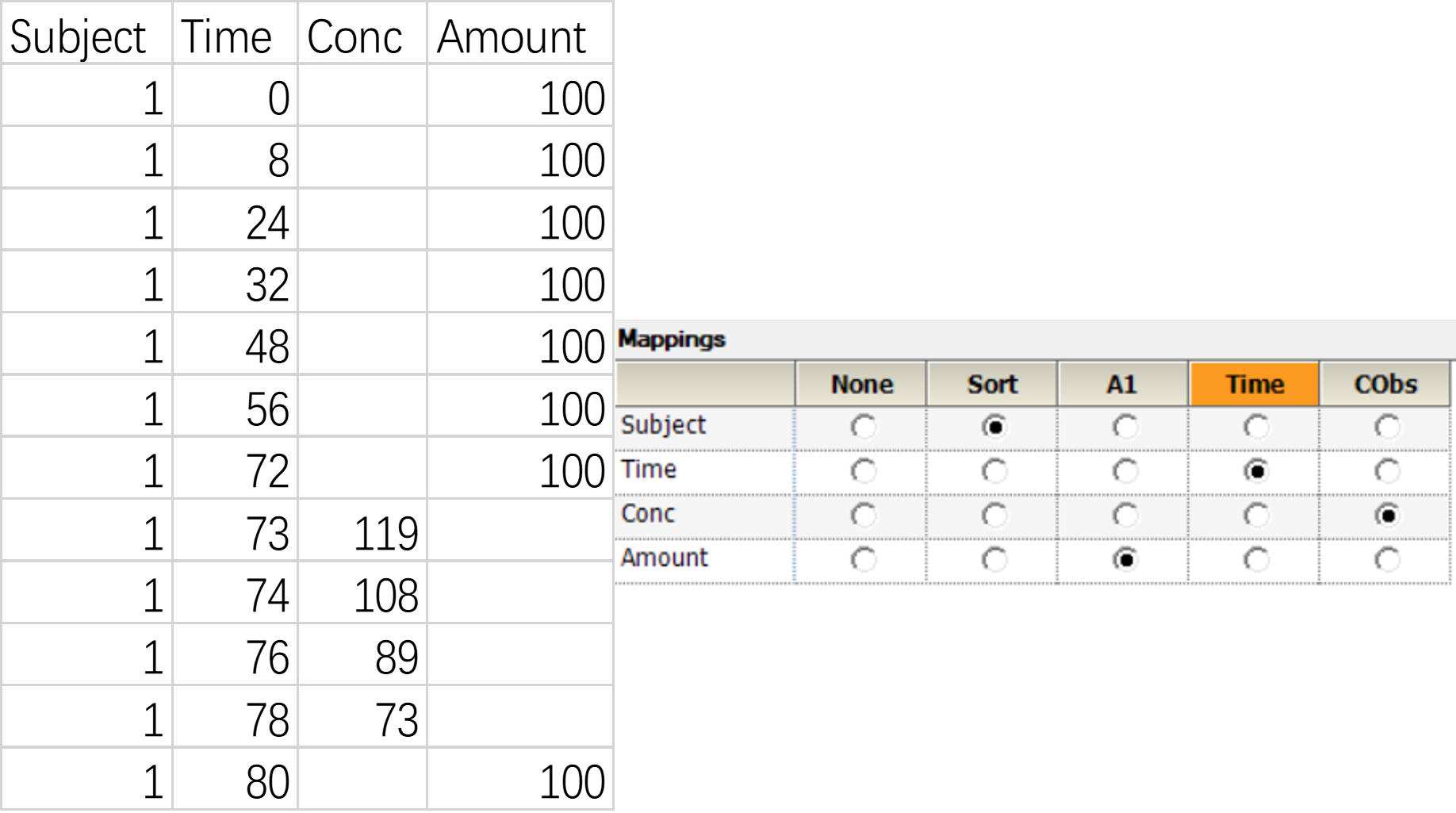
2.2.2.2使用MDV列构建数据集:
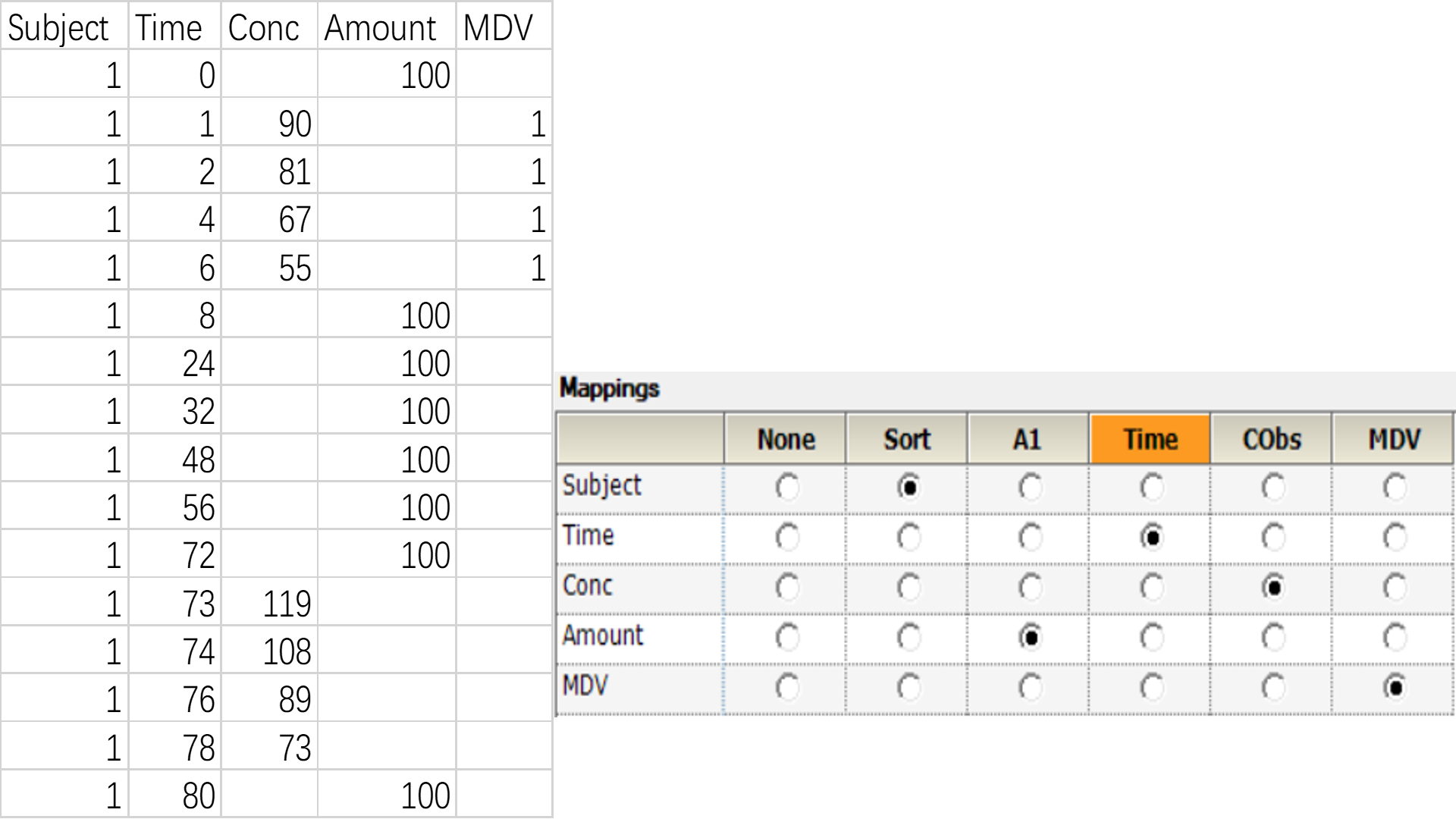
勾选“错过此因变量的观测?(MDV?)”复选框,并把”MDV”数据列映射至“MDV”字段。
2.2.3对于第二种种场景,2.2.2.1和2.2.2.2这两个数据的效果是等价的。
3.小结:
通过上述示例我们可以看出,MDV的作用其实是一种数据筛选手段;
“哪为什么不直接对数据集进行筛选,而要额外使用MDV这个数据列呢?”
这是因为,在计算机早期时代,并没有如现在Phoenix这样方便的历史记录与可视化工作流程功能,人们为了确保原始数据的一致性,所以通过在修改原始数据的情况下,通过额外新增数据标志列的方式来完成对数据筛选与分析,这在当时来说是非常好的一种手段,但对现在来说,可有可无。
Phoenix通过包含依赖关系且即时更新的工作流程,将过去被混杂在一起的数据准备、模型结构、计算方式、运行模型、结果报告等步骤,清晰的进行分离使用户在建模的时候思路清晰,线索清楚,保证灵活性的同时也保障了建模程可追溯性,极大的降低了学习群体药代动力学这门新型学科的学习曲线。


